import pandas as pd
import numpy as np
import sklearn
import pickle
import time
import datetime
import warnings
from autogluon.tabular import TabularDataset, TabularPredictor
warnings.filterwarnings('ignore')imports
df_train1 = pd.read_csv('~/Dropbox/Data/df_train1.csv')
df_train2 = pd.read_csv('~/Dropbox/Data/df_train2.csv')
df_train3 = pd.read_csv('~/Dropbox/Data/df_train3.csv')
df_train4 = pd.read_csv('~/Dropbox/Data/df_train4.csv')
df_train5 = pd.read_csv('~/Dropbox/Data/df_train5.csv')
df_train6 = pd.read_csv('~/Dropbox/Data/df_train6.csv')
df_train7 = pd.read_csv('~/Dropbox/Data/df_train7.csv')
df_train8 = pd.read_csv('~/Dropbox/Data/df_train8.csv')
df_test = pd.read_csv('~/Dropbox/Data/df_test.csv')(df_train1.shape, df_train1.is_fraud.mean()), (df_test.shape, df_test.is_fraud.mean())(((734003, 22), 0.005728859418830713), ((314572, 22), 0.005725239372862174))_df1 = pd.concat([df_train1, df_test])
_df2 = pd.concat([df_train2, df_test])
_df3 = pd.concat([df_train3, df_test])
_df4 = pd.concat([df_train4, df_test])
_df5 = pd.concat([df_train5, df_test])
_df6 = pd.concat([df_train6, df_test])
_df7 = pd.concat([df_train7, df_test])
_df8 = pd.concat([df_train8, df_test])_df1_mean = _df1.is_fraud.mean()
_df2_mean = _df2.is_fraud.mean()
_df3_mean = _df3.is_fraud.mean()
_df4_mean = _df4.is_fraud.mean()
_df5_mean = _df5.is_fraud.mean()
_df6_mean = _df6.is_fraud.mean()
_df7_mean = _df7.is_fraud.mean()
_df8_mean = _df8.is_fraud.mean()df_tr = df_train4[["amt","is_fraud"]]
df_tst = df_80[["amt","is_fraud"]]
tr = TabularDataset(df_tr)
tst = TabularDataset(df_tst)
predictr = TabularPredictor(label="is_fraud", verbosity=1)
t1 = time.time()
predictr.fit(tr)No path specified. Models will be saved in: "AutogluonModels/ag-20240520_100601/"
AutoGluon infers your prediction problem is: 'binary' (because only two unique label-values observed).
If 'binary' is not the correct problem_type, please manually specify the problem_type parameter during predictor init (You may specify problem_type as one of: ['binary', 'multiclass', 'regression'])<autogluon.tabular.predictor.predictor.TabularPredictor at 0x7f9f65c436d0>predictr.calibrate_decision_threshold()0.5predictr.predict(df_80)0 0
1 0
2 0
3 0
5 0
..
314538 0
314558 0
314563 0
314566 0
314571 0
Name: is_fraud, Length: 231011, dtype: int64yyhat_prob = predictr.predict_proba(df_80).iloc[:,-1]
yy = df_80.is_fraud_df = df_80.assign(yyhat_prob= yyhat_prob)\
.loc[:,['amt','is_fraud','yyhat_prob']]import sklearn.metricssklearn.metrics.roc_auc_score(yy,yyhat_prob)0.886678870980294_df[_df.is_fraud == 1].yyhat_prob.mean()0.3329286185951976_df[_df.is_fraud == 1].amt.mean()16.30444155844156_df[_df.is_fraud == 1].amt.hist()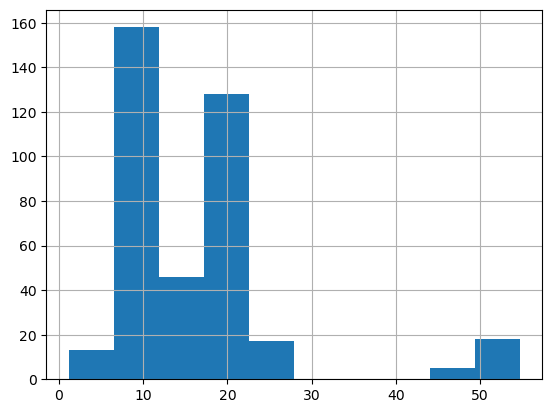
_df[_df.is_fraud == 0].yyhat_prob.mean()0.2986325147135913_df[_df.is_fraud == 0].amt.mean()31.54455620788636_df[_df.is_fraud == 0].amt.hist()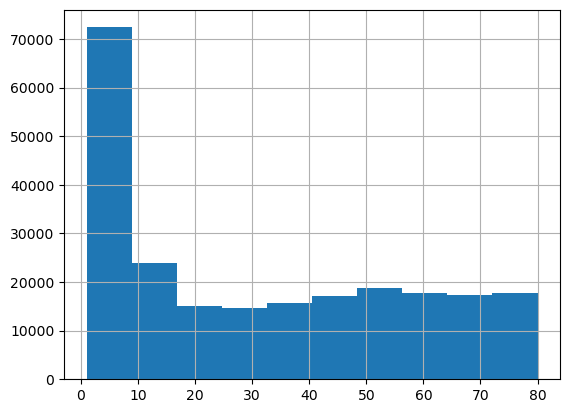
predictr.predict_proba_multi(){'KNeighborsUnif': 0 1
13979 1.0 0.0
24323 1.0 0.0
23007 1.0 0.0
37276 1.0 0.0
31070 1.0 0.0
... ... ...
36224 1.0 0.0
34032 1.0 0.0
34720 1.0 0.0
17138 1.0 0.0
25898 1.0 0.0
[2500 rows x 2 columns],
'KNeighborsDist': 0 1
13979 1.0 0.0
24323 1.0 0.0
23007 1.0 0.0
37276 1.0 0.0
31070 1.0 0.0
... ... ...
36224 1.0 0.0
34032 1.0 0.0
34720 1.0 0.0
17138 1.0 0.0
25898 1.0 0.0
[2500 rows x 2 columns],
'ExtraTreesEntr': 0 1
13979 1.0 0.0
24323 1.0 0.0
23007 1.0 0.0
37276 1.0 0.0
31070 1.0 0.0
... ... ...
36224 1.0 0.0
34032 1.0 0.0
34720 1.0 0.0
17138 1.0 0.0
25898 1.0 0.0
[2500 rows x 2 columns],
'LightGBM': 0 1
13979 0.967662 0.032338
24323 0.965496 0.034504
23007 0.969491 0.030509
37276 0.956655 0.043345
31070 0.969491 0.030509
... ... ...
36224 0.967500 0.032500
34032 0.969491 0.030509
34720 0.969491 0.030509
17138 0.967500 0.032500
25898 0.969491 0.030509
[2500 rows x 2 columns],
'RandomForestEntr': 0 1
13979 1.0 0.0
24323 1.0 0.0
23007 1.0 0.0
37276 1.0 0.0
31070 1.0 0.0
... ... ...
36224 1.0 0.0
34032 1.0 0.0
34720 1.0 0.0
17138 1.0 0.0
25898 1.0 0.0
[2500 rows x 2 columns],
'CatBoost': 0 1
13979 0.987880 0.012120
24323 0.983165 0.016835
23007 0.990823 0.009177
37276 0.963983 0.036017
31070 0.990753 0.009247
... ... ...
36224 0.972353 0.027647
34032 0.991516 0.008484
34720 0.984103 0.015897
17138 0.982423 0.017577
25898 0.987116 0.012884
[2500 rows x 2 columns],
'LightGBMLarge': 0 1
13979 0.966235 0.033765
24323 0.970804 0.029196
23007 0.970804 0.029196
37276 0.957979 0.042021
31070 0.970804 0.029196
... ... ...
36224 0.966553 0.033447
34032 0.970804 0.029196
34720 0.970804 0.029196
17138 0.970664 0.029336
25898 0.970804 0.029196
[2500 rows x 2 columns],
'NeuralNetFastAI': 0 1
13979 0.995330 0.004670
24323 0.994297 0.005703
23007 0.996624 0.003376
37276 0.888140 0.111860
31070 0.996497 0.003503
... ... ...
36224 0.914898 0.085102
34032 0.998039 0.001961
34720 0.998416 0.001583
17138 0.953835 0.046165
25898 0.998450 0.001550
[2500 rows x 2 columns],
'LightGBMXT': 0 1
13979 0.981476 0.018524
24323 0.974396 0.025604
23007 0.988903 0.011097
37276 0.972741 0.027259
31070 0.988759 0.011241
... ... ...
36224 0.986411 0.013589
34032 0.995874 0.004126
34720 0.992955 0.007045
17138 0.993169 0.006831
25898 0.994273 0.005727
[2500 rows x 2 columns],
'XGBoost': 0 1
13979 0.549148 0.450852
24323 0.549148 0.450852
23007 0.549148 0.450852
37276 0.549276 0.450724
31070 0.549148 0.450852
... ... ...
36224 0.549276 0.450724
34032 0.549148 0.450852
34720 0.549148 0.450852
17138 0.549276 0.450724
25898 0.549148 0.450852
[2500 rows x 2 columns],
'NeuralNetTorch': 0 1
13979 0.998562 0.001438
24323 0.995813 0.004187
23007 0.999538 0.000462
37276 0.979087 0.020913
31070 0.999517 0.000483
... ... ...
36224 0.993657 0.006343
34032 0.999578 0.000422
34720 0.997371 0.002629
17138 0.998840 0.001160
25898 0.997434 0.002566
[2500 rows x 2 columns],
'ExtraTreesGini': 0 1
13979 1.0 0.0
24323 1.0 0.0
23007 1.0 0.0
37276 1.0 0.0
31070 1.0 0.0
... ... ...
36224 1.0 0.0
34032 1.0 0.0
34720 1.0 0.0
17138 1.0 0.0
25898 1.0 0.0
[2500 rows x 2 columns],
'RandomForestGini': 0 1
13979 1.0 0.0
24323 1.0 0.0
23007 1.0 0.0
37276 1.0 0.0
31070 1.0 0.0
... ... ...
36224 1.0 0.0
34032 1.0 0.0
34720 1.0 0.0
17138 1.0 0.0
25898 1.0 0.0
[2500 rows x 2 columns],
'WeightedEnsemble_L2': 0 1
13979 0.711494 0.288506
24323 0.710591 0.289409
23007 0.711927 0.288073
37276 0.705633 0.294367
31070 0.711921 0.288079
... ... ...
36224 0.710353 0.289647
34032 0.711936 0.288064
34720 0.711394 0.288606
17138 0.711626 0.288374
25898 0.711410 0.288590
[2500 rows x 2 columns]}def auto_amt_ver0503(df_tr, df_tst, _df_mean):
df_tr = df_tr[["amt","is_fraud"]]
df_tst = df_tst[["amt","is_fraud"]]
tr = TabularDataset(df_tr)
tst = TabularDataset(df_tst)
predictr = TabularPredictor(label="is_fraud", verbosity=1)
t1 = time.time()
predictr.fit(tr)
t2 = time.time()
time_diff = t2 - t1
models = predictr._trainer.model_graph.nodes
results = []
for model_name in models:
# 모델 평가
eval_result = predictr.evaluate(tst, model=model_name)
# 결과를 데이터프레임에 추가
results.append({'model': model_name,
'acc': eval_result['accuracy'],
'pre': eval_result['precision'],
'rec': eval_result['recall'],
'f1': eval_result['f1'],
'auc': eval_result['roc_auc']})
model = []
time_diff = []
acc = []
pre = []
rec = []
f1 = []
auc = []
graph_based = []
method = []
throw_rate = []
train_size = []
train_cols = []
train_frate = []
test_size = []
test_frate = []
hyper_params = []
for result in results:
model_name = result['model']
model.append(model_name)
time_diff.append(None) # 각 모델별로 학습한 시간을 나타내고 싶은데 잘 안됨
acc.append(result['acc'])
pre.append(result['pre'])
rec.append(result['rec'])
f1.append(result['f1'])
auc.append(result['auc'])
graph_based.append(False)
method.append('Autogluon')
throw_rate.append(_df_mean)
train_size.append(len(tr))
train_cols.append([col for col in tr.columns if col != 'is_fraud'])
train_frate.append(tr.is_fraud.mean())
test_size.append(len(tst))
test_frate.append(tst.is_fraud.mean())
hyper_params.append(None)
df_results = pd.DataFrame(dict(
model=model,
time=time_diff,
acc=acc,
pre=pre,
rec=rec,
f1=f1,
auc=auc,
graph_based=graph_based,
method=method,
throw_rate=throw_rate,
train_size=train_size,
train_cols=train_cols,
train_frate=train_frate,
test_size=test_size,
test_frate=test_frate,
hyper_params=hyper_params
))
ymdhms = datetime.datetime.fromtimestamp(time.time()).strftime('%Y%m%d-%H%M%S')
df_results.to_csv(f'../results2/{ymdhms}-Autogluon.csv',index=False)
return df_resultsamt 80 미만 잘 잡는지 확인용..
df_80 = df_test[df_test['amt'] <= 80]df_80.shape, df_80.is_fraud.mean()((231011, 22), 0.0016665873053664112)_df1_ = pd.concat([df_train1, df_80])
_df2_ = pd.concat([df_train2, df_80])
_df3_ = pd.concat([df_train3, df_80])
_df4_ = pd.concat([df_train4, df_80])
_df5_ = pd.concat([df_train5, df_80])
_df6_ = pd.concat([df_train6, df_80])
_df7_ = pd.concat([df_train7, df_80])
_df8_ = pd.concat([df_train8, df_80])_df1_mean_ = _df1_.is_fraud.mean()
_df2_mean_ = _df2_.is_fraud.mean()
_df3_mean_ = _df3_.is_fraud.mean()
_df4_mean_ = _df4_.is_fraud.mean()
_df5_mean_ = _df5_.is_fraud.mean()
_df6_mean_ = _df6_.is_fraud.mean()
_df7_mean_ = _df7_.is_fraud.mean()
_df8_mean_ = _df8_.is_fraud.mean()